
爬虫基础01
爬虫基础01
1.引入requests
爬虫基础阶段最重要的包。
1 | import requests |
2.使用requests访问目标网址
以爬取豆瓣为例。
get方法里面有三个参数,分别为 url、请求头、请求参数。
1 | url = 'https://m.douban.com/rexxar/api/v2/movie/recommend' |
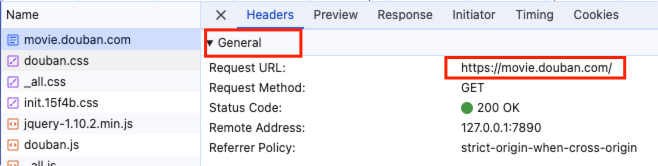
获取请求网址
可以在浏览器开发者工具,也可以在地址栏获取。
获取请求头
最重要3个:User-agent、Referer、Cookie
这三个可以在 Request Headers 里面获取。

!!!重点,利用工具网站 https://curlconverter.com/ 直接生成。
找到要访问的ajax请求,然后复制curl。
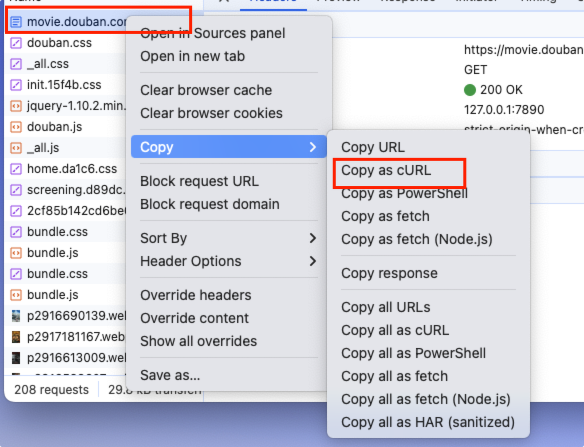
粘贴到网站,然后复制其成的格式。
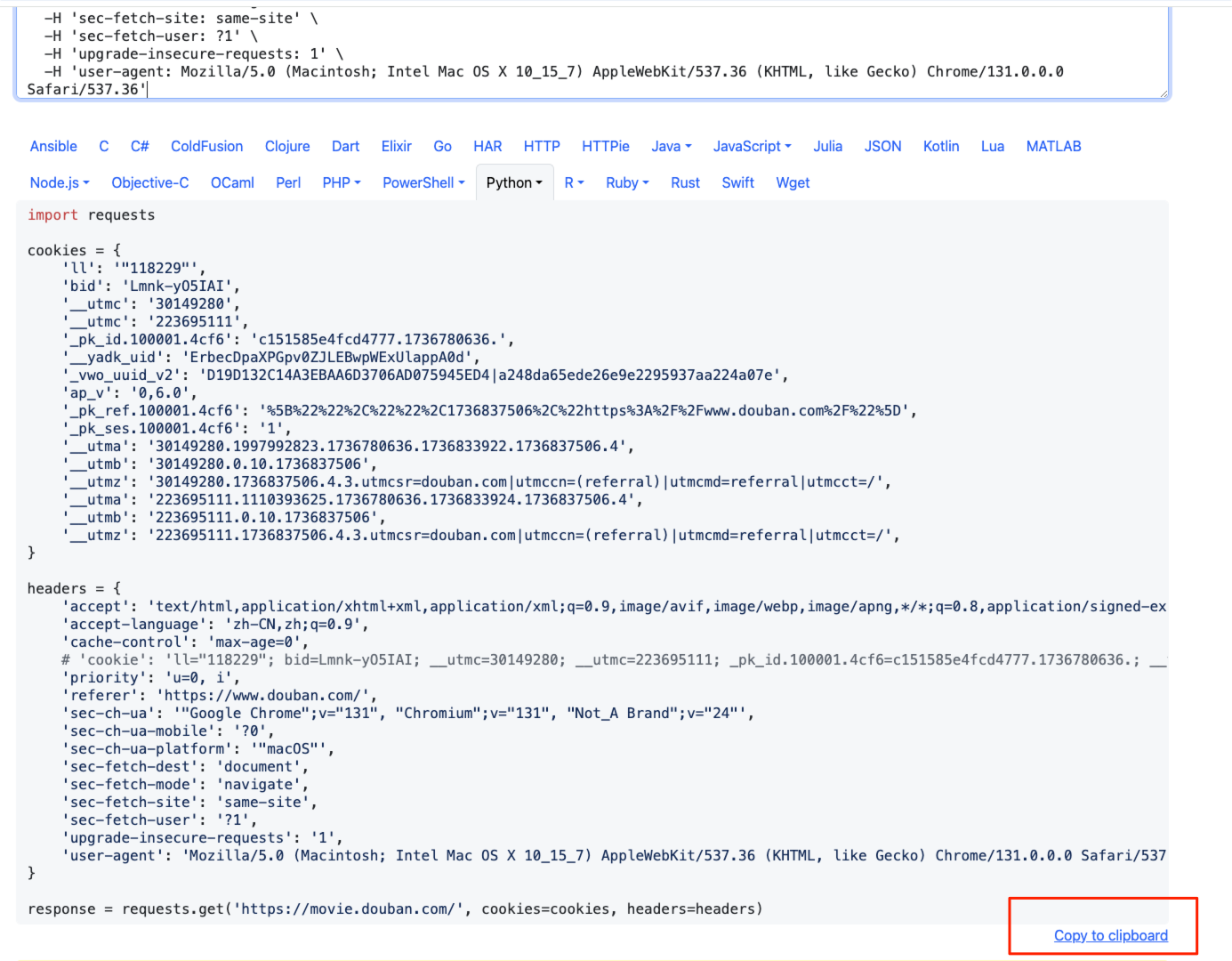
直粘贴到 python文件中。
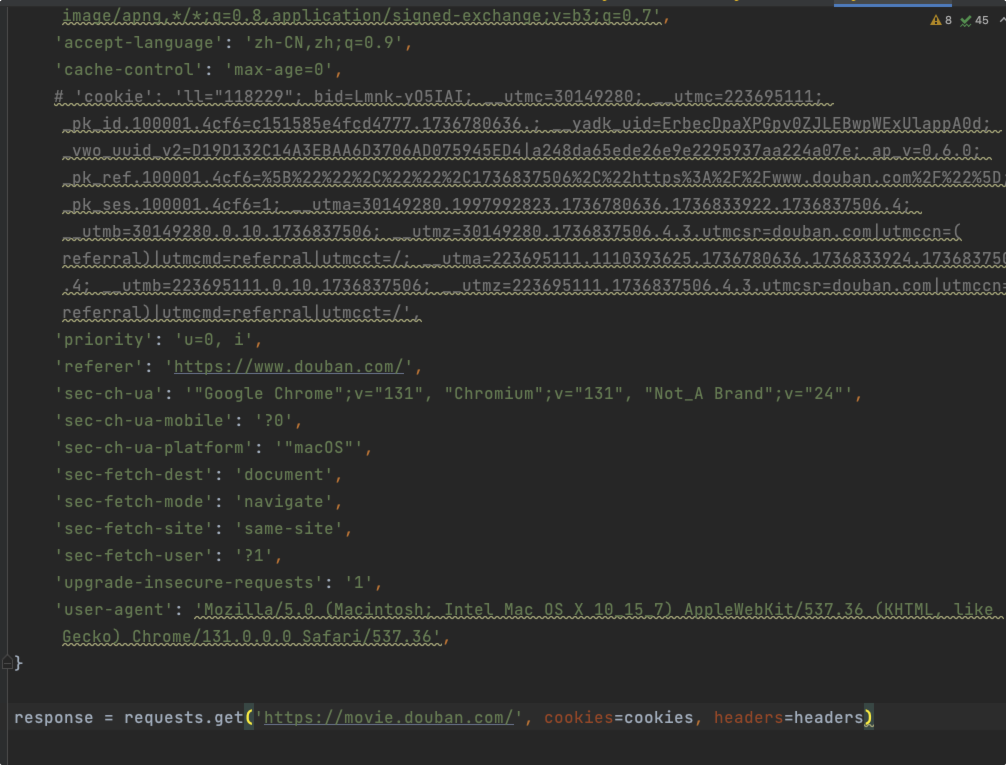
获取请求参数
自己观察url格式,进行判断
3.访问资源并保存
这里以科幻系列为例。
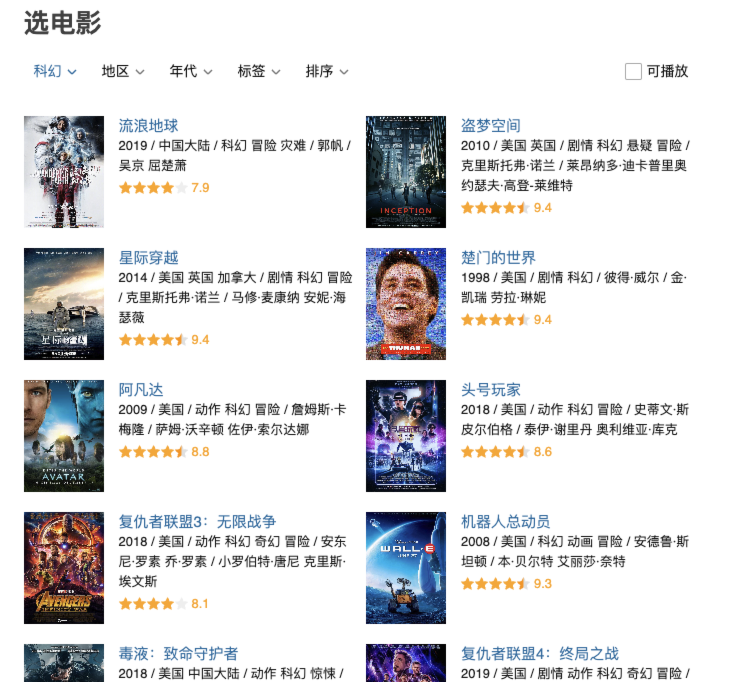
找到页面对应的ajax请求,然后进行「获取请求头」,在预览中找到数据格式。
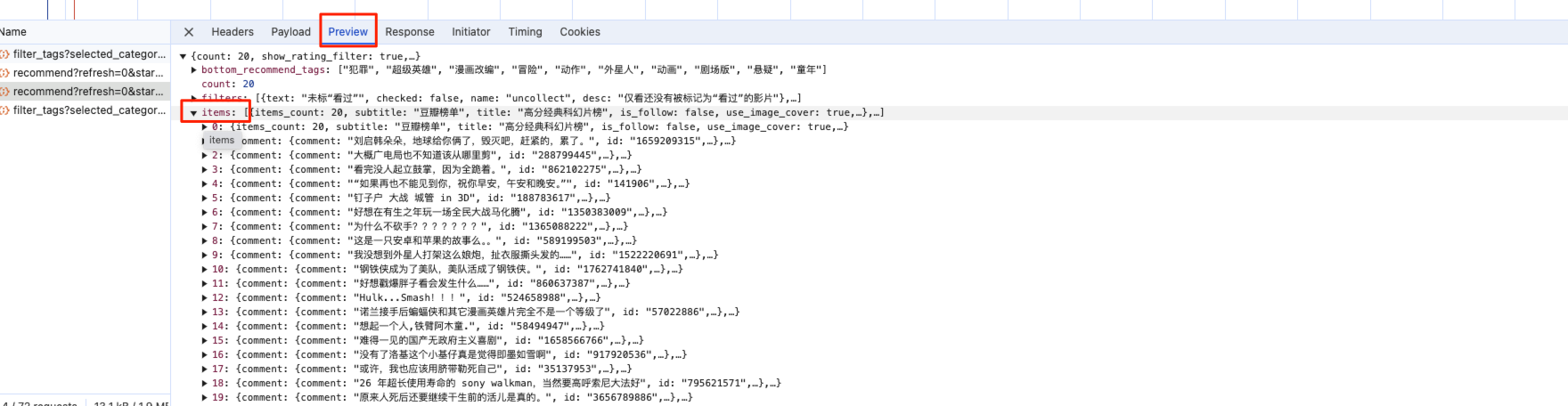
然后获取数据,进行输出保存。
1 | list1 = response.json().get('items') |
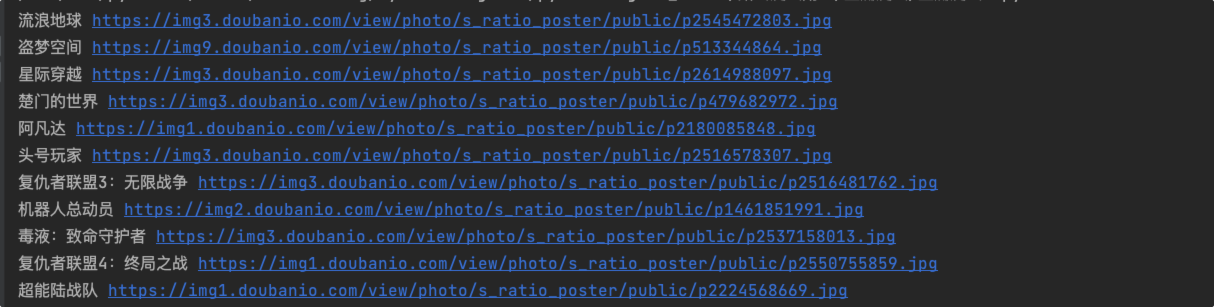
进行数据保存,这里以图片保存为例。

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 知还。!
评论

