建立目标检测模型
设计网络模型
概要
输入: 图片Resize 448 * 448
输出:预测目标上的一个目标/物体

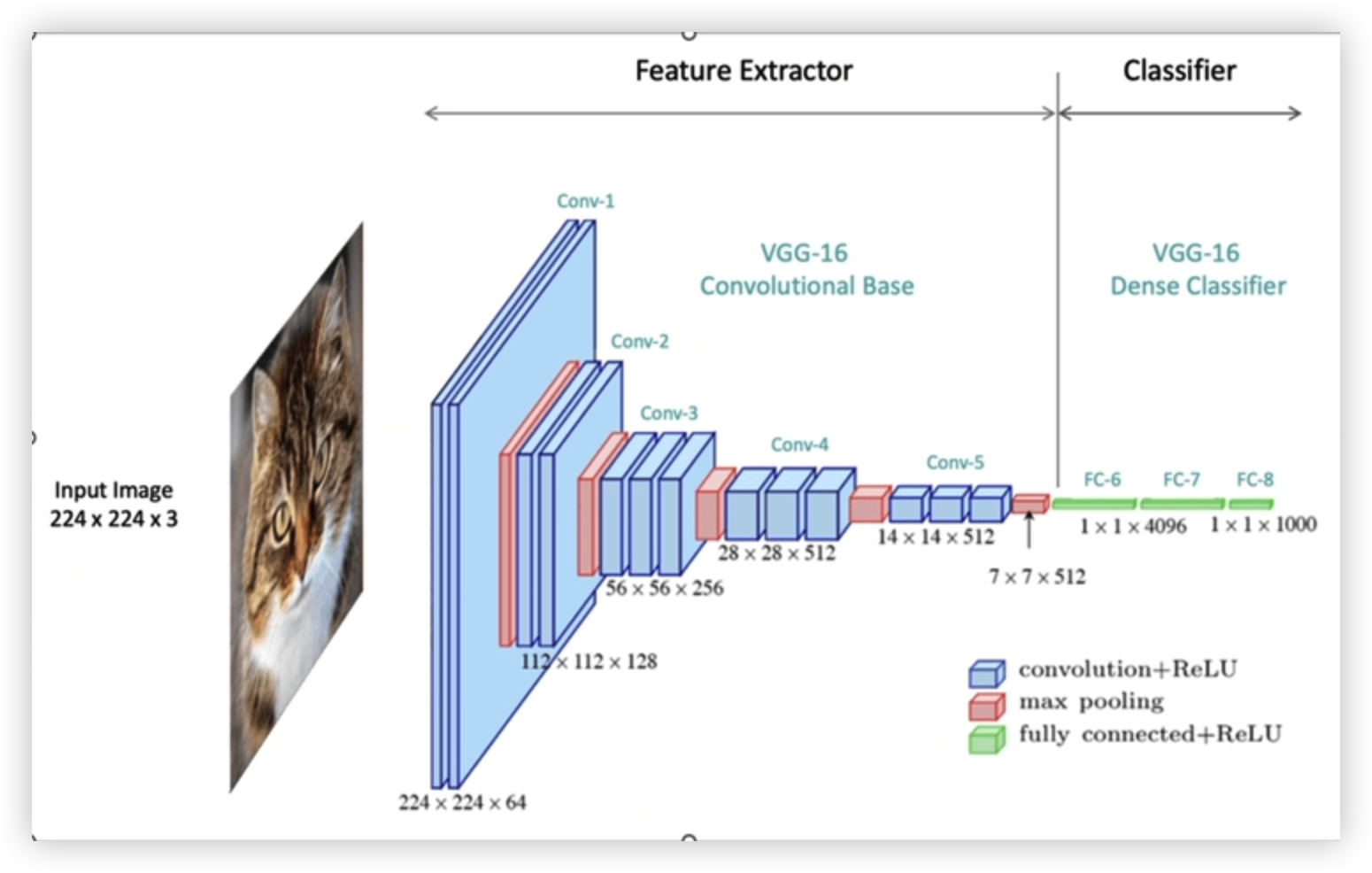
可以借助经典模型的部分框架
例如VGG16(经典模型,按照自己需求舍去图像分类部分)
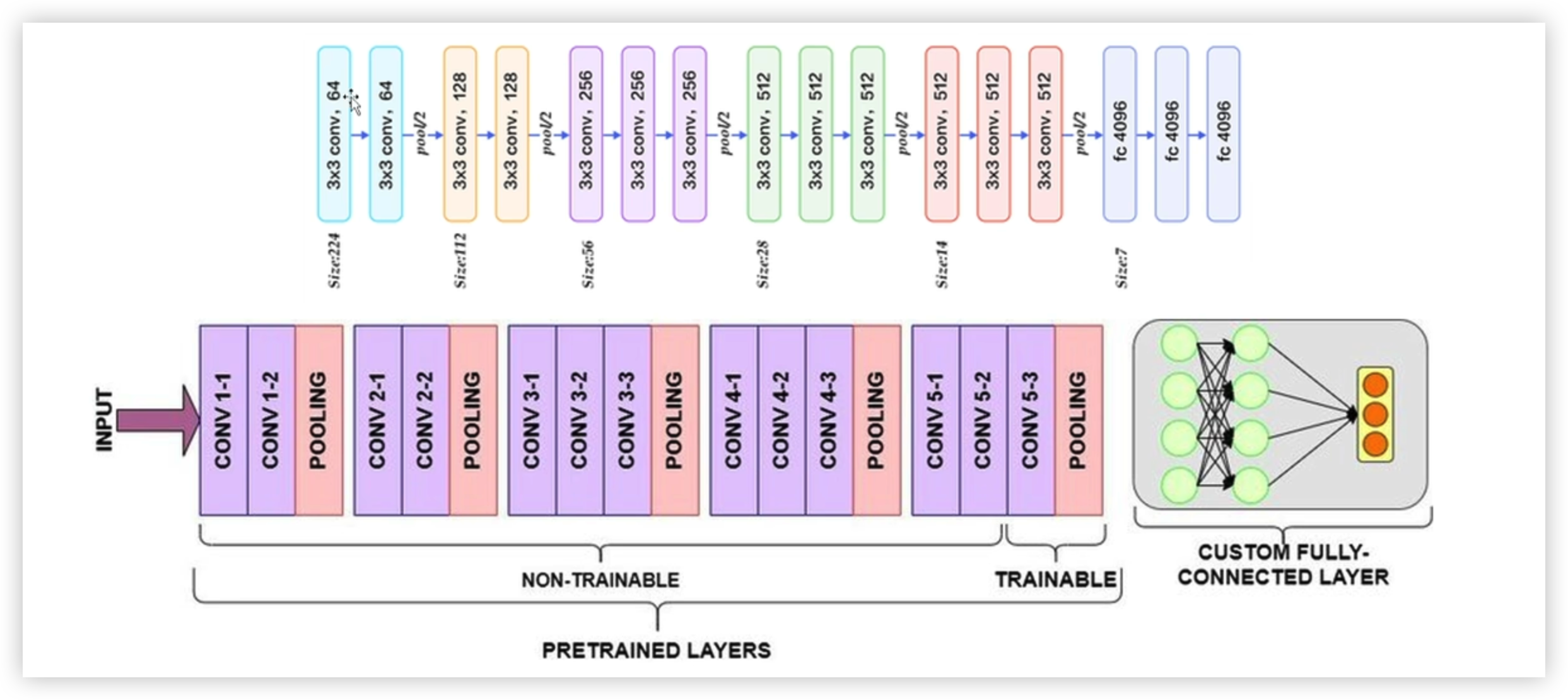
利用前面的特征提取,舍去后面的分类
目标检测模型架构
主干 — 颈部 — 头部
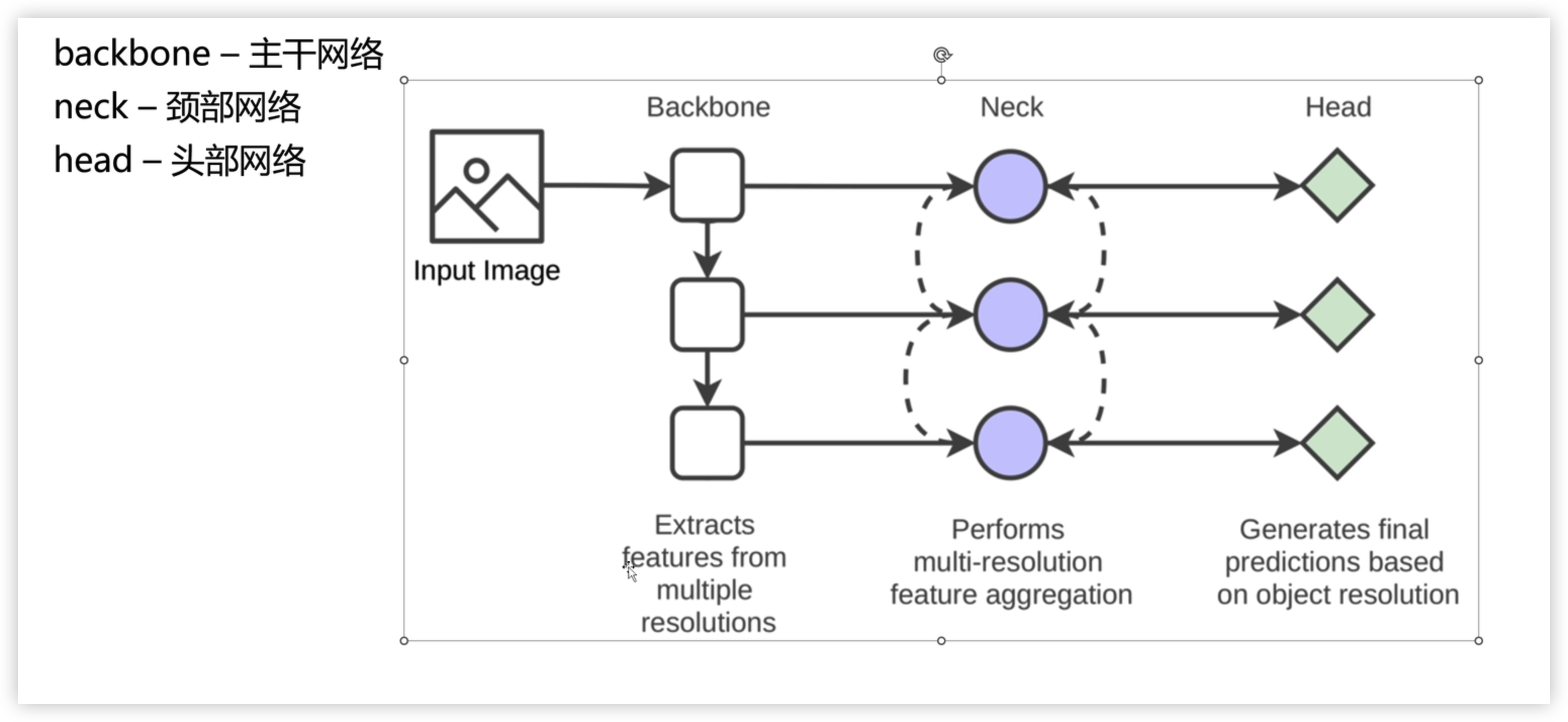
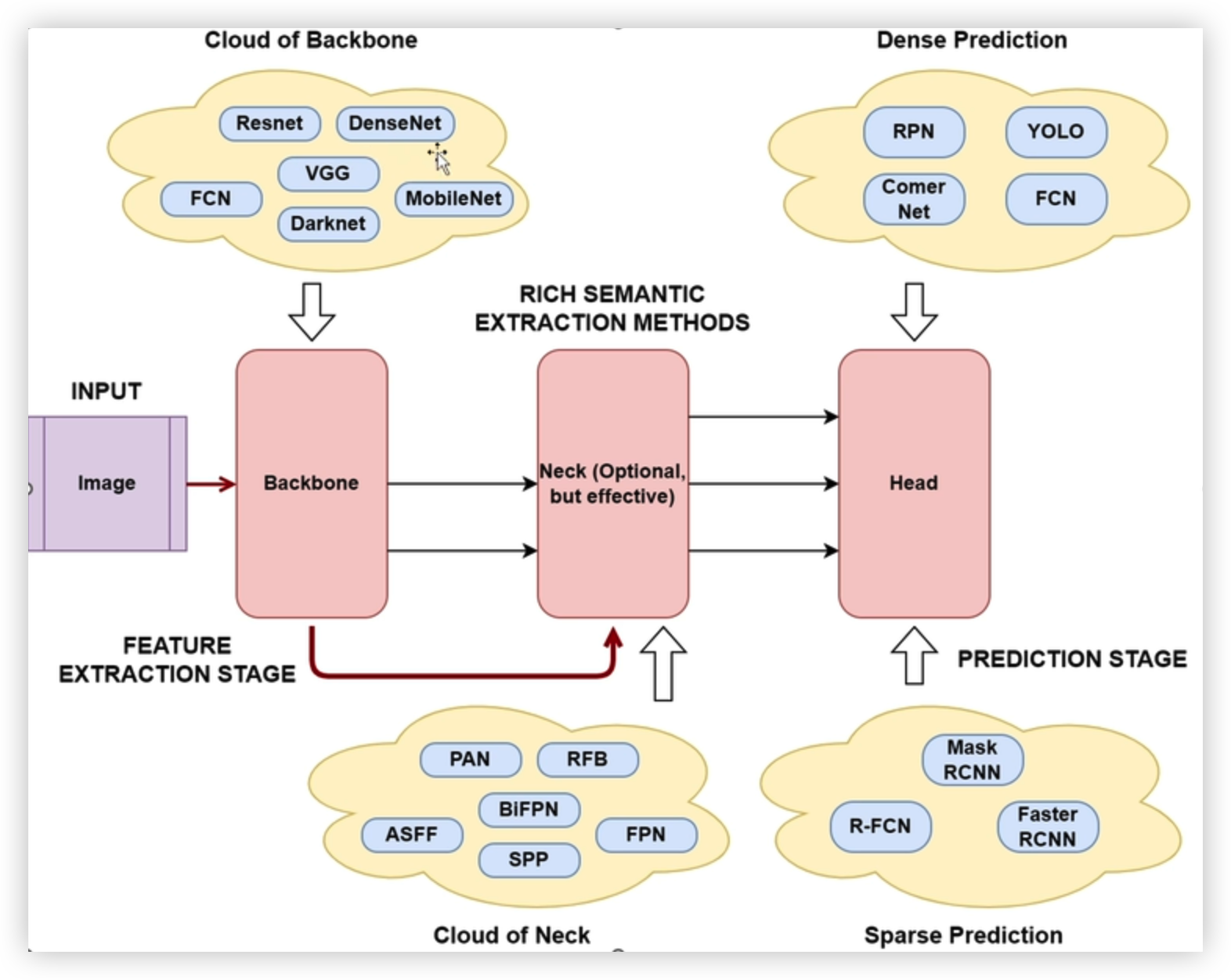
1. Backbone – 主干网络
核心作用:从输入图像中提取多尺度、多层次的特征。
工作方式:
- 像 CNN、ResNet、VGG、ViT 这类网络,会逐步下采样图像,生成不同分辨率的特征图。
- 浅层特征保留细节(如边缘、纹理),深层特征保留语义(如物体类别、整体结构)。
类比:相当于人的视觉皮层,先把看到的画面拆解成各种基础视觉元素。
2. Neck – 颈部网络
核心作用:对 Backbone 输出的多尺度特征进行融合与增强,实现多分辨率特征聚合。
工作方式:
- 常见结构如 FPN、PANet、BiFPN,通过上采样 + 下采样的路径,让不同层级的特征互相传递信息。
- 解决 “小物体特征太弱、大物体特征太粗” 的问题,让每个尺度的特征都包含丰富的上下文信息。
类比:相当于人的视觉中枢,把零散的视觉元素整合成更有意义的视觉片段。
3. Head – 头部网络
核心作用:基于 Neck 处理后的特征,生成最终的目标检测结果。
工作方式:
分为两个子任务:
- 分类头:判断每个特征点对应的物体类别。
- 回归头:预测物体的边界框坐标(x, y, w, h)。
不同分辨率的特征图会对应不同大小的物体(大特征图测小物体,小特征图测大物体)。
类比:相当于人的视觉决策区,根据整合后的信息判断 “这是什么东西、在哪里”。
✨ 整体流程总结
- 输入图像 → Backbone:提取多尺度特征。
- 多尺度特征 → Neck:融合增强,生成更鲁棒的多分辨率特征。
- 增强后特征 → Head:输出物体的类别与位置。
实现模型
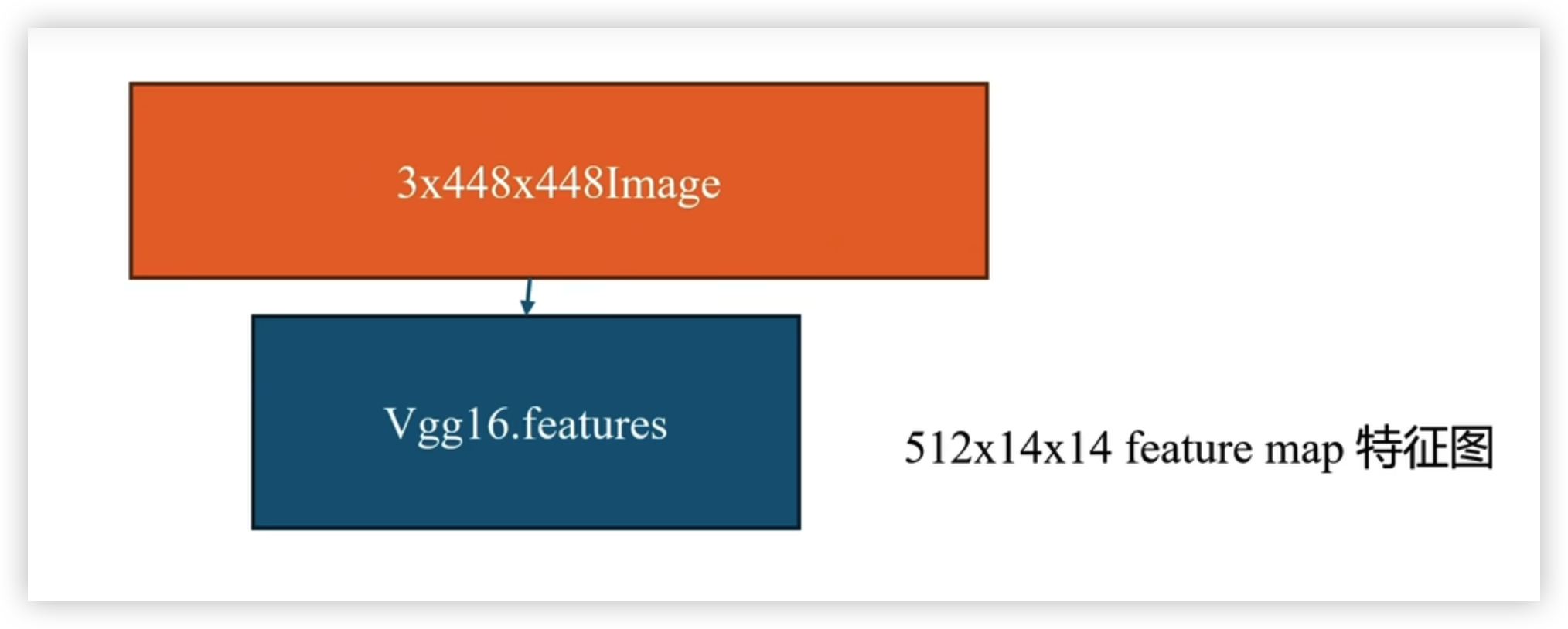
1.利用 vgg16的特征提取部分,舍去其他(例如图像分类部分)
1 | from torch import nn |
输入 一张 随机的 448 * 448 RGB 三通道的图
变成一张 14 * 14 的 521通道的特征图
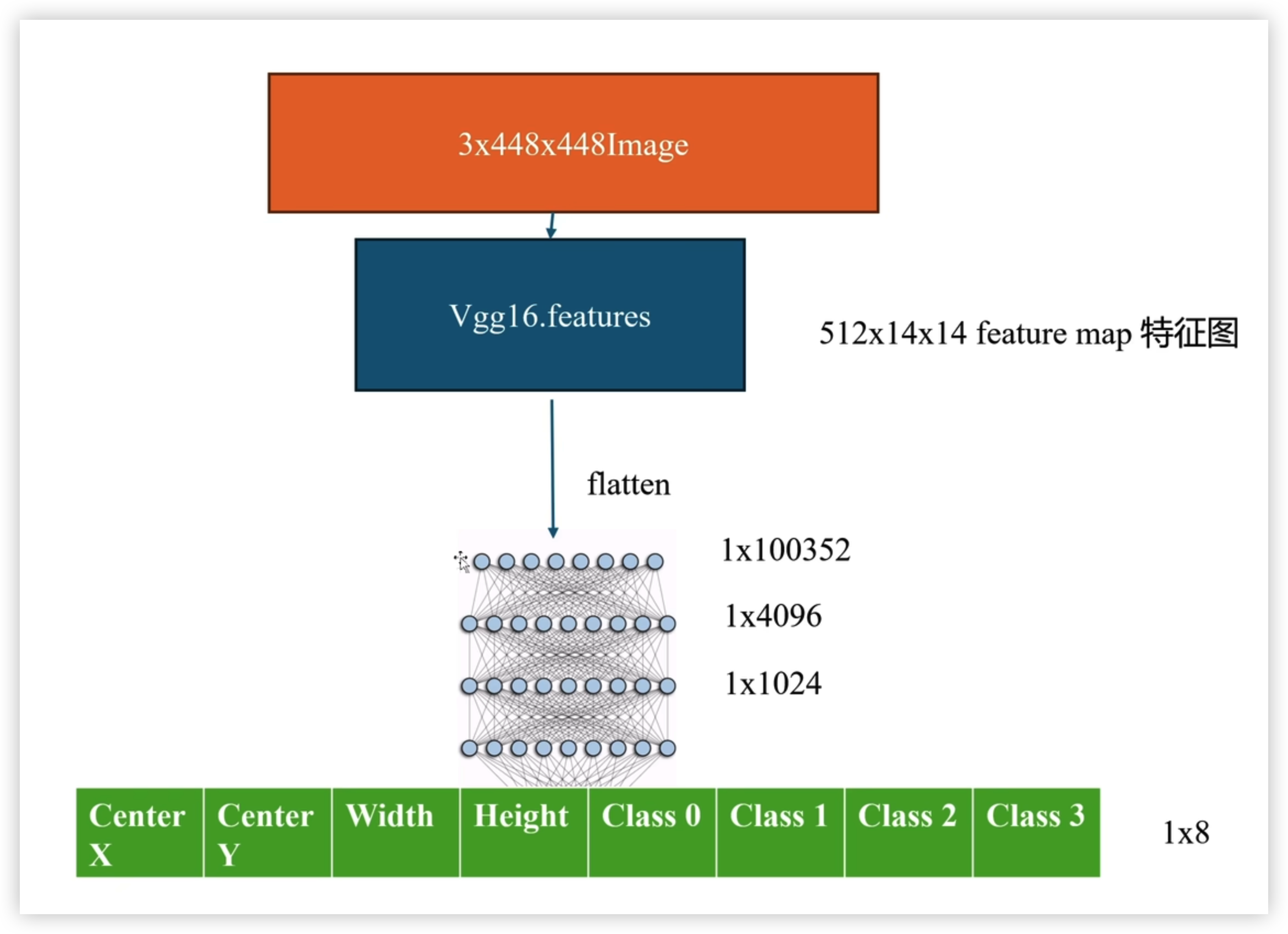
利用全连接层进行输出形式转换
先展平
512 * 14 * 14 = 100352
1 | from torch import nn |
实现损失函数
目标检测核心损失函数总结
目标检测的损失函数分为两大核心部分:回归损失(边界框损失) 和分类损失,分别对应 “找位置” 和 “辨类别” 两个任务,下面用通俗易懂的方式梳理核心知识点:
一、回归损失(边界框损失)
1. 核心作用
衡量模型预测的边界框(Center X/Y、宽 / 高)与真实标注框之间的数值误差,让模型学会精准定位目标。
2. 常用类型及特点
| 损失函数 | 中文名称 | 适用场景 | 核心特点 |
|---|---|---|---|
nn.MSELoss() |
均方误差损失 | 简单回归场景 | 计算预测值与真实值的平方差,对异常值(离群点)敏感 |
nn.SmoothL1Loss() |
平滑 L1 损失 | 目标检测首选 | 结合 L1(对异常值鲁棒)和 L2(梯度平滑)的优点:- 误差小时(<1):等价于 MSE,梯度平滑;- 误差大时:等价于 L1,避免梯度爆炸 |
| IoU Loss/GIoU Loss | IoU 损失 / 广义 IoU 损失 | 高精度定位 | 直接基于边界框的交并比计算损失,更贴合 “检测准不准” 的直观判断,解决传统回归对坐标偏移不敏感的问题 |
3. 关键注意事项
- 回归输出层无激活函数,保留连续实数输出(如归一化后的坐标值);
- 真实标注框需先做归一化(如除以图像宽高),让预测值和真实值在同一尺度(0~1)。
二、分类损失
1. 核心作用
衡量模型预测的类别概率分布与真实类别之间的分布差异,让模型学会正确识别目标类别。
2. 常用类型及特点
| 损失函数 | 中文名称 | 适用场景 | 核心特点 |
|---|---|---|---|
nn.CrossEntropyLoss() |
交叉熵损失 | 单标签分类(目标检测主流) | 集成了Softmax+NLLLoss:- 输入为模型原始输出(logits,无激活);- 自动将 logits 转为概率分布,计算与真实标签的交叉熵;- 真实标签为类别索引(如 0/1/2/3),非 one-hot 编码 |
nn.BCELoss() |
二元交叉熵损失 | 多标签分类 / 二分类 | 需手动在模型输出层加Sigmoid激活,真实标签为 one-hot 编码(如 [1,0,0,0]) |
nn.BCEWithLogitsLoss() |
带 Logits 的二元交叉熵 | 多标签分类(更推荐) | 内置Sigmoid,输入为 logits,避免手动激活导致的数值不稳定 |
3. 关键注意事项
- 单标签分类(目标检测常见)优先用
CrossEntropyLoss,模型输出层不加 Softmax; - 推理阶段需对 logits 加
F.softmax(dim=1),得到和为 1 的类别概率; - 多标签分类(一个目标可能属于多个类别)用
BCEWithLogitsLoss。
总结
- 回归损失:聚焦 “位置准不准”,首选
SmoothL1Loss(鲁棒性强),输出层无激活,拟合连续实数坐标; - 分类损失:聚焦 “类别对不对”,单标签用
CrossEntropyLoss(输入 logits),多标签用BCEWithLogitsLoss; - 目标检测总损失 = 回归损失权重 × 回归损失 + 分类损失权重 × 分类损失(权重可根据任务调整,通常回归损失权重更高)。
在目标检测任务中,90% 以上的经典 / 主流场景里,大家都会优先选择以下组合,这也是工业界和学术界最通用、最稳定的搭配:
一、核心组合(首选)
| 任务类型 | 首选损失函数 | 核心原因 |
|---|---|---|
| 边界框回归(找位置) | nn.SmoothL1Loss() |
1. 对标注噪声 / 异常值(比如标注框画偏了)鲁棒,不会像 MSE 那样梯度爆炸;2. 误差小时梯度平滑,训练收敛更稳定;3. 是 Faster R-CNN、YOLOv3/v5、SSD 等经典模型的默认选择 |
| 单标签分类(辨类别) | nn.CrossEntropyLoss() |
1. 集成 Softmax + 交叉熵,无需手动处理概率,避免数值不稳定;2. 适配 “一个目标只属于一个类别” 的绝大多数检测场景;3. PyTorch 封装完善,调用简单,训练效率高 |
二、特殊场景的替代选择
只有遇到以下情况,才需要换其他损失:
- 回归损失替代:
- 追求更高精度的定位(如自动驾驶、工业检测)→
GIoU Loss/DIoU Loss/CIoU Loss(比 SmoothL1 更贴合 IoU 指标); - 简单小数据集、无标注噪声 → 偶尔用
nn.MSELoss()(计算更快)。
- 追求更高精度的定位(如自动驾驶、工业检测)→
- 分类损失替代:
- 多标签分类(一个目标属于多个类别,比如 “猫 + 宠物 + 动物”)→
nn.BCEWithLogitsLoss(); - 二分类场景(只有 “有目标 / 无目标”)→
nn.BCEWithLogitsLoss()(比 CrossEntropy 更轻量)。
- 多标签分类(一个目标属于多个类别,比如 “猫 + 宠物 + 动物”)→
三、考研复试背诵
MSELoss 是均方误差损失,它对误差进行平方处理,优点是计算简单、梯度光滑,但缺点是对异常值非常敏感,误差大的时候容易出现梯度爆炸,训练不稳定。
SmoothL1Loss 结合了 L1 损失和 L2 损失的优点:
当误差较小时,使用均方误差,保证梯度平滑;
当误差较大时,使用绝对值损失,限制梯度范围,对异常值和噪声更鲁棒。
所以在目标检测这种真实场景、标注可能存在噪声的任务里,SmoothL1Loss 是更常用、更稳定的选择。
- 追求训练稳定、抗噪声、精度更高 → 用 SmoothL1
- 追求计算快、简单、数据干净 → 用 MSE(L2)
损失函数详解过程
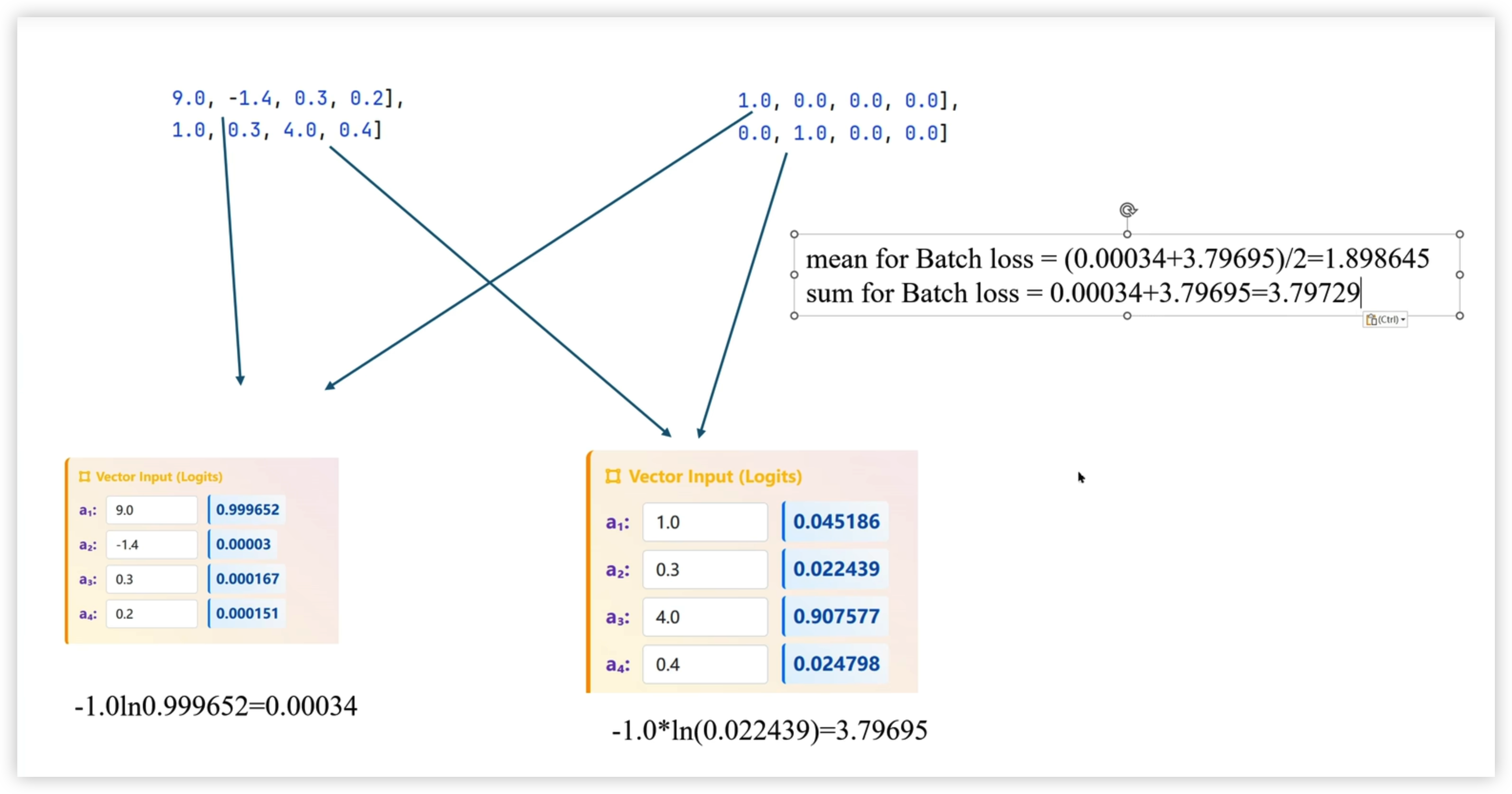
利用输出结果,按批次进行损失函数计算 batch_loss
每张图片进过模型可以得出一个输出,这里是一行八列(输出形式自己可以定义)
这里的 batch=2 , 然后两张一起计算损失
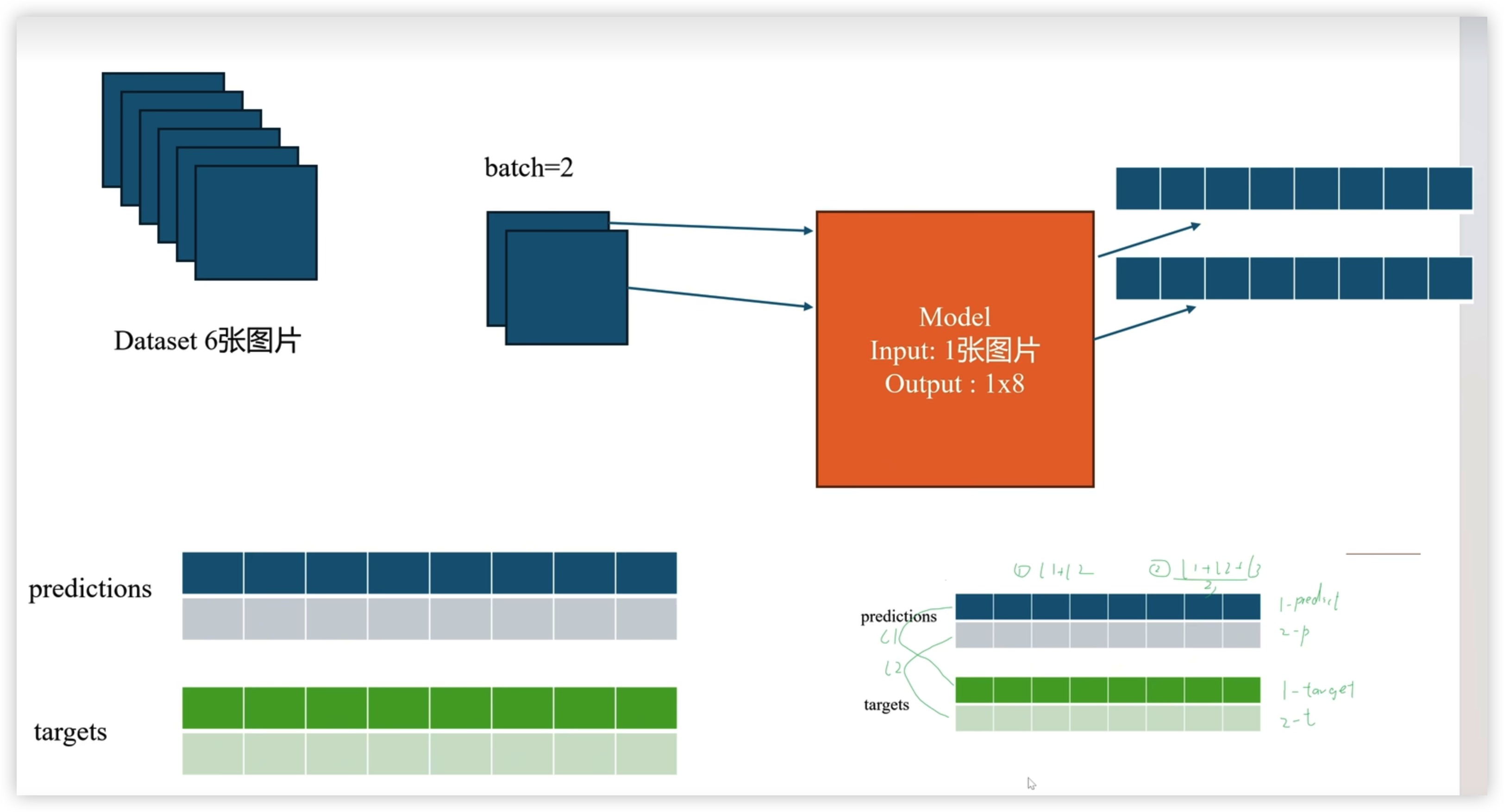
损失函数是利用模型预测的值 与 人工标注的值 进行某种数学运算得到的
MSE Loss(均方误差损失,Mean Squared Error Loss)是回归任务中最常用的损失函数,我会用通俗语言 + 数学公式 + 代码验证帮你彻底理解它的计算逻辑。
一、MSE Loss 核心公式(默认是求平均值 reduction=”mean”)
MSE Loss 的本质是:预测值与目标值差值的平方,再求平均值(默认)。
1. 基础数学公式
对于单个样本(比如你的位置预测):
MSE=n1∑i=1n(ypred,i−ytarget,i)2
- n:样本的特征维度(比如预测 x/y 两个坐标,n=2)
- ypred,i:第 i 个维度的预测值
- ytarget,i:第 i 个维度的目标值
2. 批量样本的公式(实际训练中)
如果是一批数据(batch),默认会先计算每个样本的 MSE,再对整个 batch 求平均:
Batch MSE=B×n1∑b=1B∑i=1n(ypred,b,i−ytarget,b,i)2
- B:batch size(批量大小)
3.代码
1 | import torch |

二、交叉熵损失(Cross Entropy Loss)
交叉熵损失(Cross Entropy Loss)是分类任务(尤其是多分类)的核心损失函数,我会从公式含义、分类场景、PyTorch 对应实现三个维度讲清楚,兼顾数学理解和实际使用。
交叉熵损失的本质是衡量 “模型预测的概率分布” 与 “真实标签分布” 的差异,差异越小(损失值越低),预测越准。
先区分两个关键场景:
- 二分类:只有两个类别(如 0/1、正 / 负)
- 多分类:多个类别(如数字识别 0-9、图像分类 1000 类)
一、数学公式(分场景)
1. 单样本二分类交叉熵
真实标签 y∈{0,1},模型预测为正类的概率 p∈(0,1):
CE=−[y⋅log(p)+(1−y)⋅log(1−p)]
- y=1 时:损失 = −log(p)(p 越接近 1,损失越小)
- y=0 时:损失 = −log(1−p)(p 越接近 0,损失越小)
2. 单样本多分类交叉熵(最常用)
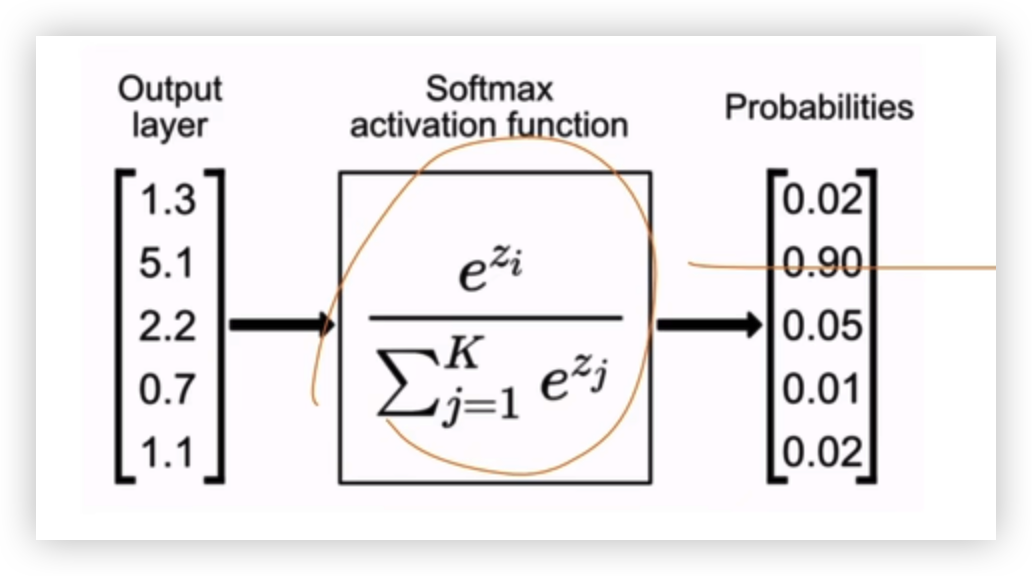
真实标签是独热编码(比如 3 分类中,标签为第 2 类则 y=[0,1,0]),模型预测的概率分布 y^=[y^1,y^2,…,y^n](需通过 Softmax 归一化到 0-1,且和为 1):
CE=−∑i=1nyi⋅log(y^i)
- n:类别总数
- yi:真实标签的第 i 位(独热编码,只有目标类为 1,其余为 0)
- y^i:模型预测第 i 类的概率
👉 简化版(非独热标签):
实际使用中,真实标签通常是类别索引(比如 3 分类中标签为 2),公式可简化为:
CE=−log(y^k)
其中 k 是真实类别索引(只需要计算目标类的预测概率的负对数)。
3. 批量样本交叉熵(训练中)
对一批样本(batch size = B)的交叉熵取均值:
Batch CE=−B1∑b=1B∑i=1nyb,i⋅log(y^b,i)
二、直观例子(多分类)
假设:
- 类别数 n=3,真实标签是第 2 类(独热编码 y=[0,1,0])
- 模型预测概率(Softmax 后)y^=[0.1,0.8,0.1]
手动计算:
CE=−(0⋅log(0.1)+1⋅log(0.8)+0⋅log(0.1))=−log(0.8)≈0.223
如果模型预测更准(y^=[0.01,0.98,0.01]):
CE=−log(0.98)≈0.020
(损失值更小,符合预期)
三、分类损失函数计算需要注意的问题
需要进行 Softmax activation function 才能将结果转为概率,而CrossEntropyLoss 自动进行了这一步
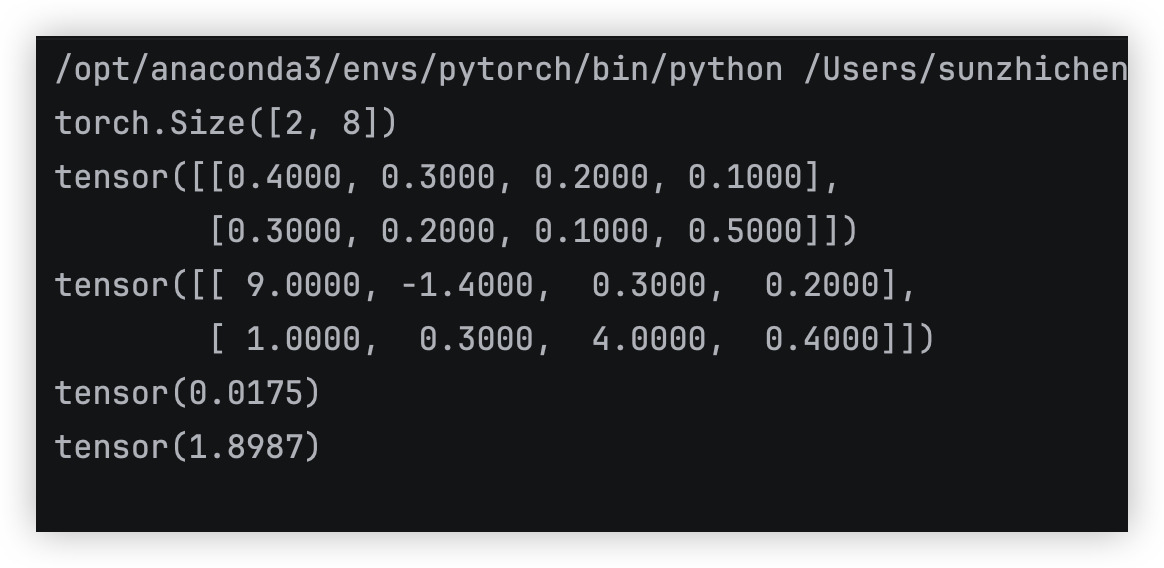
算出交叉熵损失