
深度学习
深度学习
简介
一、核心背景(顶层红色文字)
“机器学习在处理图像和文本数据方面,能力较弱”
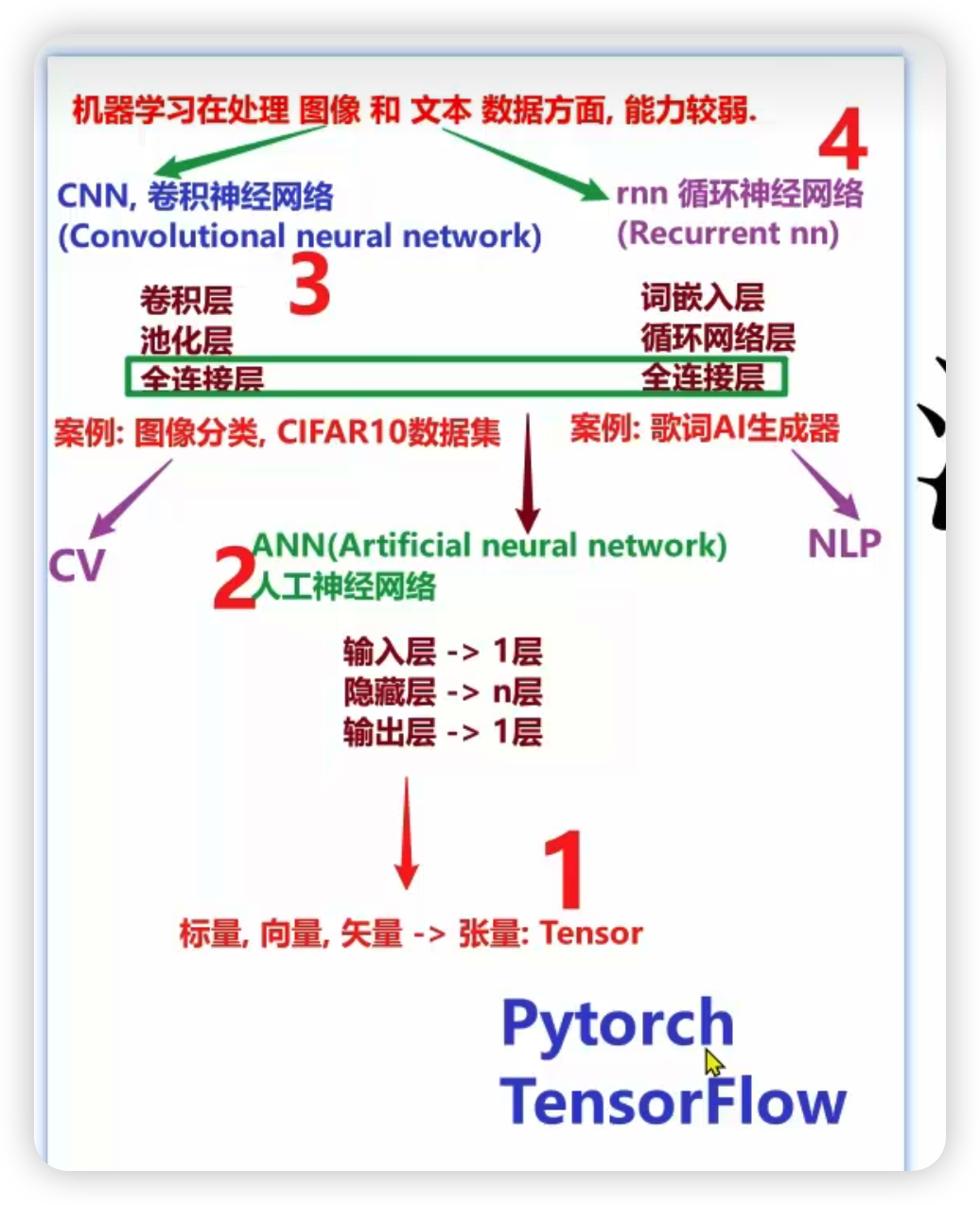
这是整个知识点的前提:传统机器学习(如逻辑回归、SVM、随机森林)擅长处理结构化数据(如表格、数值),但对非结构化数据 (多维)(图像、文本、语音)的特征提取能力不足 —— 无法自动捕捉图像的边缘 / 纹理、文本的上下文语义,因此需要专门的深度学习模型来解决。
二、两大核心解决方案(架构对应与分工)
图片通过绿色箭头,将两种非结构化数据与对应的神经网络一一匹配,实现了 “问题 - 解法” 的精准对应:
表格
| 数据类型 | 对应模型 | 英文全称 | 核心定位 |
|---|---|---|---|
| 图像 | CNN(卷积神经网络) | Convolutional Neural Network | 专攻空间特征提取(如图像的形状、颜色、局部纹理) |
| 文本 | RNN(循环神经网络) | Recurrent Neural Network | 专攻时序特征提取(如文本的上下文顺序、语义关联) |
三、模型核心结构(技术底层)
两种网络的核心层分工明确,分别适配对应数据的特性:
CNN 的核心层
- 卷积层:核心层,通过卷积核滑动提取图像的局部特征(如边缘、角点),实现 “权值共享”,减少模型参数;
- 池化层:下采样层,压缩特征图尺寸,保留关键特征的同时降低计算量(如最大池化、平均池化);
- 全连接层:收尾层,将提取的局部特征整合,输出最终分类 / 检测结果。
RNN 的核心层
- 词嵌入层:将离散的文字 / 词语转化为连续的数值向量(Embedding),让模型能理解文本的语义;
- 循环网络层:核心层,通过 “循环反馈” 机制,保留前一时刻的文本信息,捕捉上下文关联;
- 全连接层:整合时序特征,输出文本生成、分类等结果。
四、典型应用案例(实践落地)
图片给出了最经典的入门级案例,直观体现模型的实际用途:
CNN 案例:图像分类(CIFAR10 数据集)
CIFAR10 是计算机视觉入门标杆数据集,包含 10 类常见物体(如飞机、汽车、猫、狗)的彩色小图像,CNN 是解决该数据集分类问题的标准模型。
RNN 案例:歌词 AI 生成器
利用 RNN 的时序记忆能力,学习歌词的韵律、句式和上下文逻辑,从而自动生成符合风格的歌词,是文本生成任务的典型入门场景。
补充说明(知识拓展)
这张图是入门级简化梳理,实际应用中已有更优方案:
- 图像领域:CNN 已发展出 ResNet、ViT(视觉 Transformer)等更强大的模型;
- 文本领域:RNN 存在 “长序列梯度消失” 问题,目前主流用 LSTM、GRU(RNN 的改进版)或 Transformer(大语言模型的核心)替代。
五、深度学习特点


六、深度学习计算框架
- PyTorch:目前非常主流的深度学习框架,以动态计算图、易用性和灵活性著称,在学术界和工业界都被广泛使用,尤其适合研究和快速原型开发。
- TensorFlow:被标注为 “旧版框架”,它是 Google 推出的老牌框架,以静态计算图和生产部署能力见长,现在更多被其升级版本 Keras 或 TensorFlow 2.x 所继承使用。
七、 Transformer 模型
- 这是深度学习领域的里程碑式架构,核心是自注意力机制(Self-Attention),能够同时处理序列中的所有位置,解决了 RNN 等模型难以处理长序列的问题。
- 它的应用场景非常广泛,包括:
- 机器翻译(如 Google Translate 的核心)
- 文本摘要、问答系统
- 大语言模型(如 GPT、BERT 系列)
- 计算机视觉(如 ViT,Vision Transformer)
应用场景
一、计算机视觉(Computer Vision)
这是深度学习在图像、视频等视觉数据上的应用,核心是让机器 “看懂” 世界。
图像分类
- 定义:将输入图像划分到预定义的类别中。
- 应用:人脸识别、物体检测、社交媒体照片自动标注、医疗影像中的病变检测(如 CT、X 光片识别病灶)。
目标检测(Object Detection)
- 定义:在图像或视频中同时完成 “定位”(找到物体位置)和 “分类”(识别物体是什么)两个任务。
- 应用:自动驾驶中的行人 / 车辆检测、监控视频中的入侵检测、电商商品识别。
面部识别
- 定义:通过提取和比对面部特征点,完成身份验证或人脸分类。
- 应用:手机人脸解锁、安防监控系统、机场 / 车站的身份核验。
图像生成
- 定义:基于输入(如文本、参考图)生成全新的图像或对现有图像进行编辑。
- 应用:艺术风格迁移(如把照片变成油画)、老旧照片修复、图像超分辨率(把模糊图变清晰)、AI 绘画(如 Stable Diffusion)。
二、自然语言处理(Natural Language Processing, NLP)
1. 机器翻译
- 定义:使用深度学习模型将一种语言的文本自动翻译成另一种语言。
- 典型应用:Google 翻译、实时语音翻译(如跨国会议、旅游翻译)。
- 技术背景:从早期的统计机器翻译(SMT)发展到现在的 Transformer 架构(如 Google 的 GNMT),翻译质量大幅提升。
2. 情感分析
- 定义:分析文本中的情感倾向,判断其为正面、负面或中性。
- 典型应用:社交媒体监控(舆情分析)、电商产品评论分析、用户满意度调查。
- 技术背景:常用方法包括基于词典的规则匹配、传统机器学习(如 SVM)和深度学习(如 LSTM、BERT)。
3. 文本生成
- 定义:生成符合语法和语义的自然语言文本。
- 典型应用:自动写作助手(如 Grammarly、Notion AI)、新闻生成、小说创作、代码生成。
- 技术背景:核心是大语言模型(LLM),如 GPT 系列,通过学习海量文本数据来生成连贯、有意义的文本。
4. 语音识别
- 定义:将语音转化为文字(ASR,Automatic Speech Recognition)。
- 典型应用:智能助手(Siri、Alexa)、自动字幕生成(视频平台)、语音输入法。
- 技术背景:结合了声学模型和语言模型,深度学习(如 CNN、RNN、Transformer)大幅提升了识别准确率。
5. 聊天机器人(Chatbot)
- 定义:通过深度学习理解用户输入并生成合理的回应。
- 典型应用:客服机器人(电商、金融)、虚拟助手(如 GPT 类模型)、陪伴式聊天。
- 技术背景:从早期的规则匹配到现在的检索式 + 生成式混合模型,再到端到端的大语言模型,交互越来越自然。
三、推荐系统
1. 电影、音乐推荐
- 定义:根据用户历史评分、播放 / 观看记录、收藏等行为数据,推荐符合其偏好的电影、音乐或剧集。
- 典型应用:Netflix(影视推荐)、Spotify(音乐推荐)、网易云音乐 “每日推荐”。
- 技术背景:常用协同过滤(基于用户 / 物品相似度)、矩阵分解、深度学习(如 DeepFM、Neural Collaborative Filtering)等方法。
2. 电商推荐
- 定义:基于用户的购买历史、浏览轨迹、购物车、搜索关键词等数据,推荐相关商品,提升转化率和客单价。
- 典型应用:亚马逊 “Customers who bought this also bought”、淘宝 “猜你喜欢”、京东个性化首页。
- 技术背景:结合用户画像、商品画像和场景特征,使用排序模型(如 LR、XGBoost、Deep & Cross Network)进行精准推荐。
3. 社交媒体推荐
- 定义:分析用户的社交关系(好友、关注 / 粉丝)、互动行为(点赞、评论、转发)、内容偏好,推荐相关内容(帖子、视频)或潜在好友。
- 典型应用:Facebook/Instagram 的信息流推荐、抖音 “推荐页”、微博 “热门推荐”。
- 技术背景:融合图神经网络(GNN)建模社交关系,结合用户兴趣漂移模型,实现实时、动态的内容分发。
四、多模态大模型
机器学习 & 深度学习 一句话区别
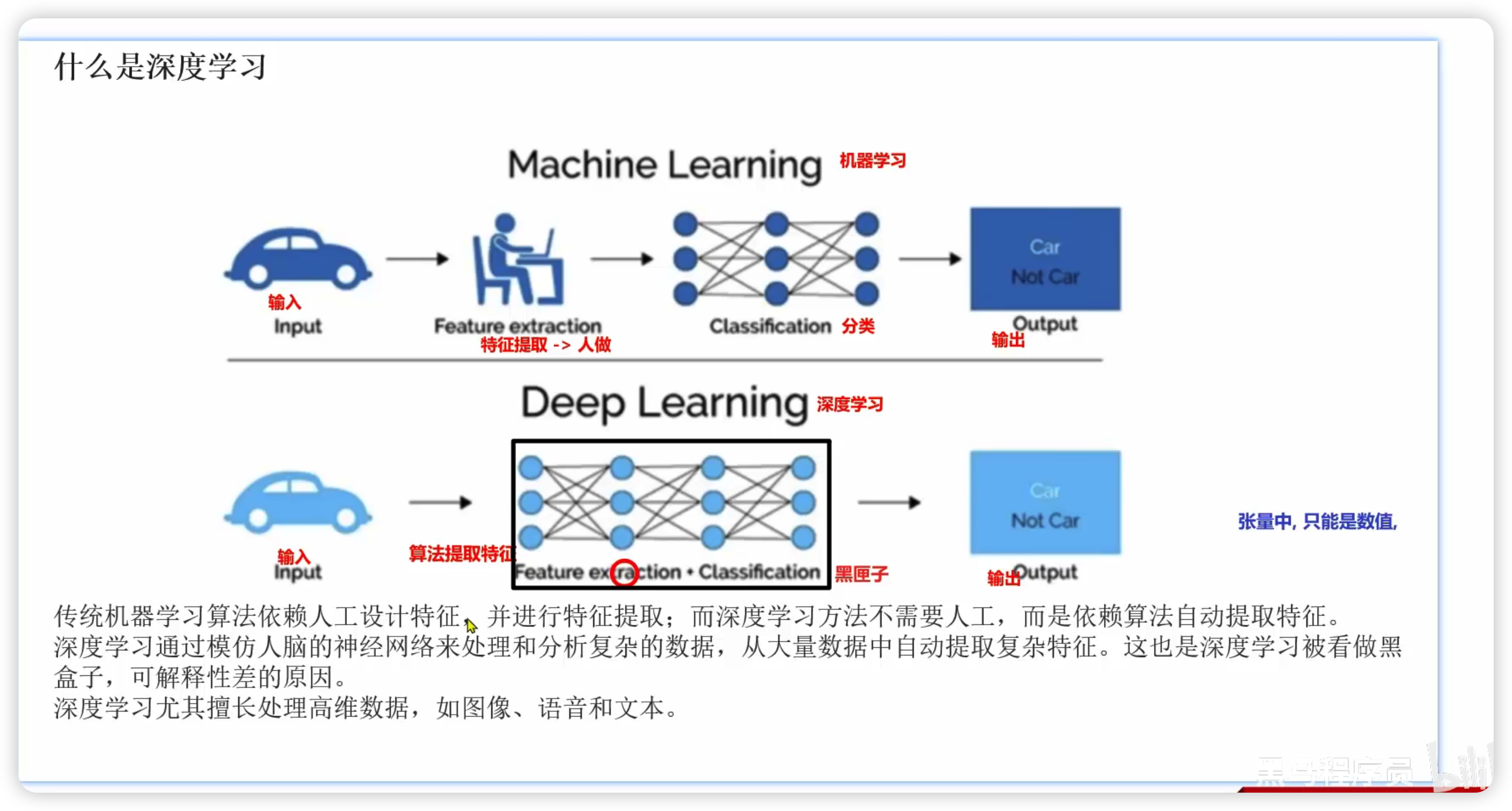
深度学习是机器学习的一个分支,只是层次更深、自动提取特征。
核心区别(超清晰对比)
1. 特征提取
机器学习:需要人工提取特征
比如:你要告诉模型图片哪里是边缘、颜色、纹理。
深度学习:自动提取特征
模型自己学边缘、纹理、形状、高级语义,不用人手工设计。
2. 数据量
- 机器学习:小数据也能用
- 深度学习:需要大量数据,数据少效果差
3. 计算资源
- 机器学习:普通电脑 CPU 就能跑
- 深度学习:需要 GPU,计算量大
4. 模型结构
- 机器学习:模型浅(逻辑回归、SVM、决策树)
- 深度学习:模型很深(多层神经网络:CNN、RNN、Transformer)
5. 适用数据
- 机器学习:擅长 表格数据、结构化数据
- 深度学习:擅长 图像、文本、语音、视频 这类非结构化数据
6. 可解释性
- 机器学习:容易解释
- 深度学习:黑盒,很难解释
最简单记忆口诀
- 机器学习 = 人工找特征 + 简单模型
- 深度学习 = 自动找特征 + 深层神经网络
一句话总结(考试直接背)
机器学习是让机器从数据学习规律的方法总称;深度学习是基于多层神经网络、能自动提取特征的机器学习方法,主要用于图像、文本、语音等复杂任务。
PyTorch

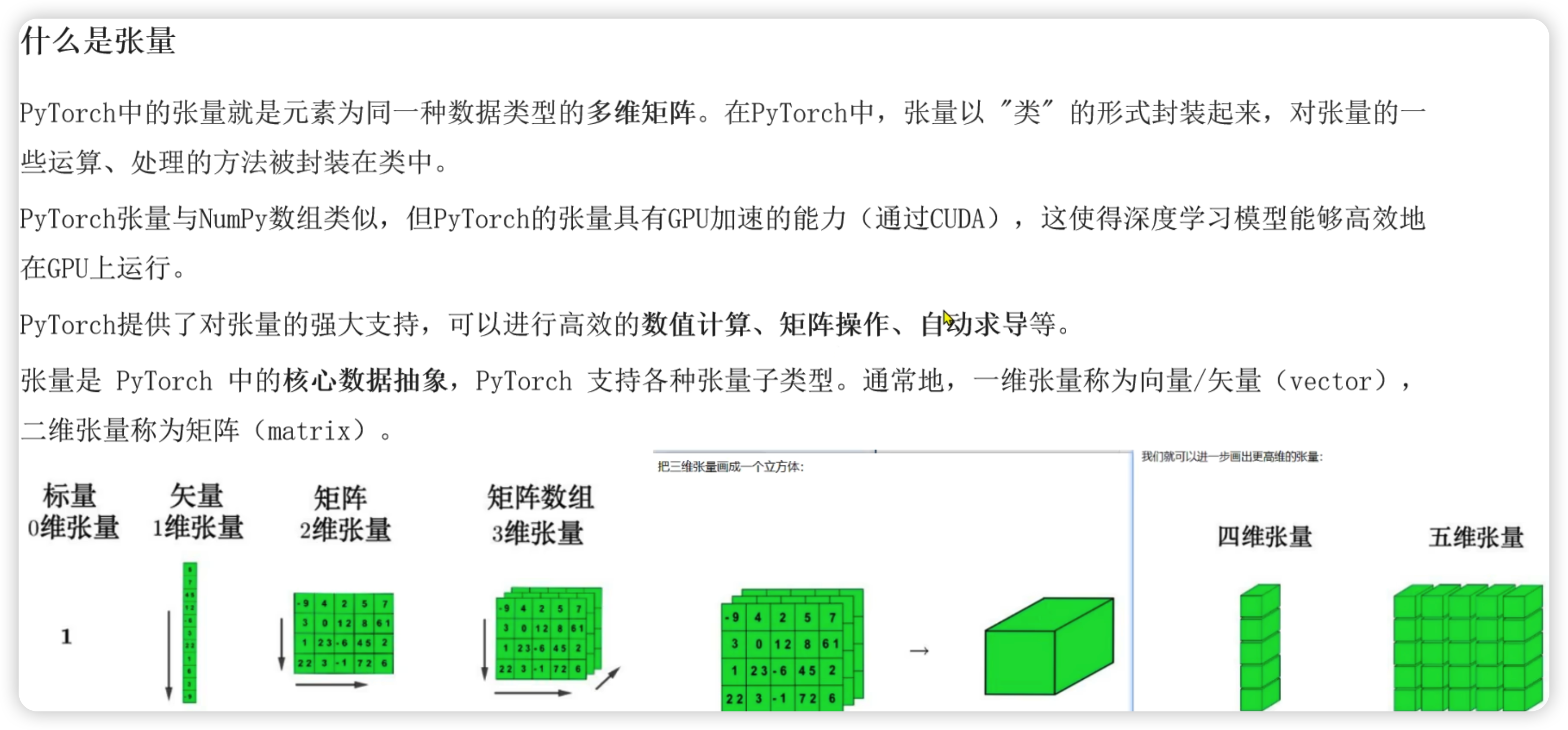
张量
CIFAR10模型
手动实现图片模型
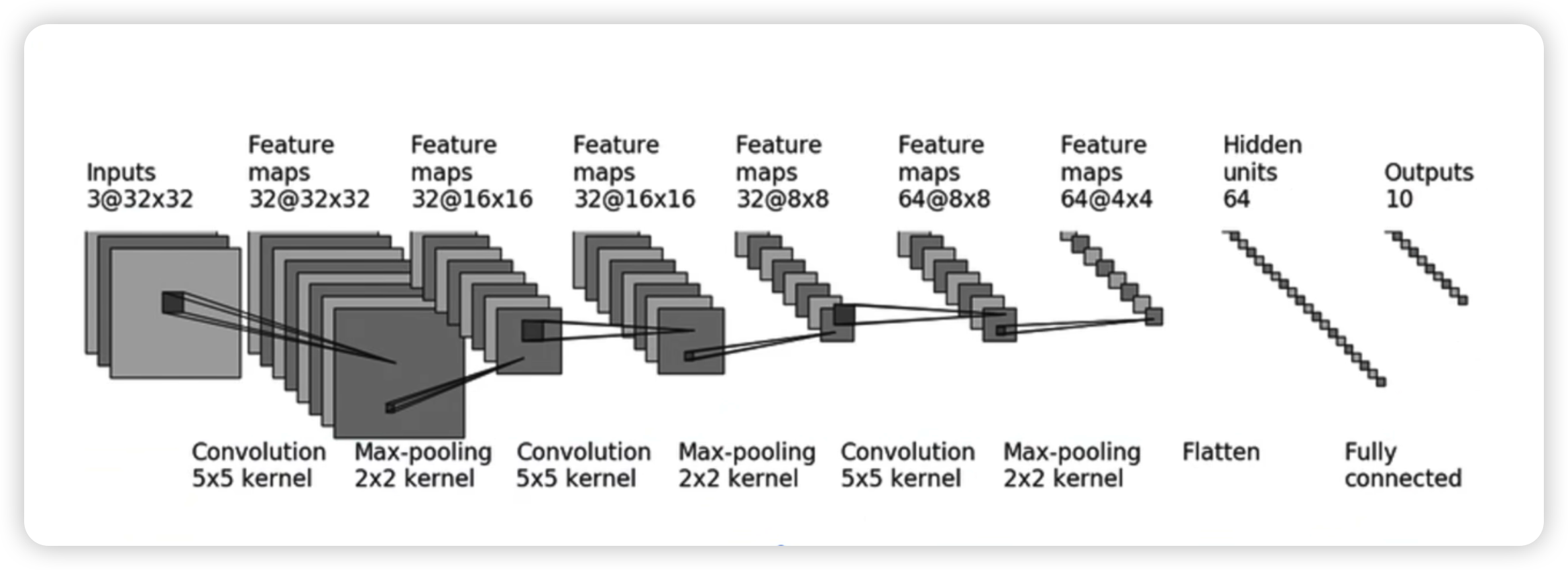
卷积1 + 池化1

$$ {得出结论}
得出结论
(1)stride = 1,padding =2
$$
1 | self.conv1 = Conv2d(3, 32, 5, stride=1, padding=2) |
卷积2 + 池化2 + 后续
$$
(2)stride = 1,padding = 10
$$
1 |
|
注意力机制
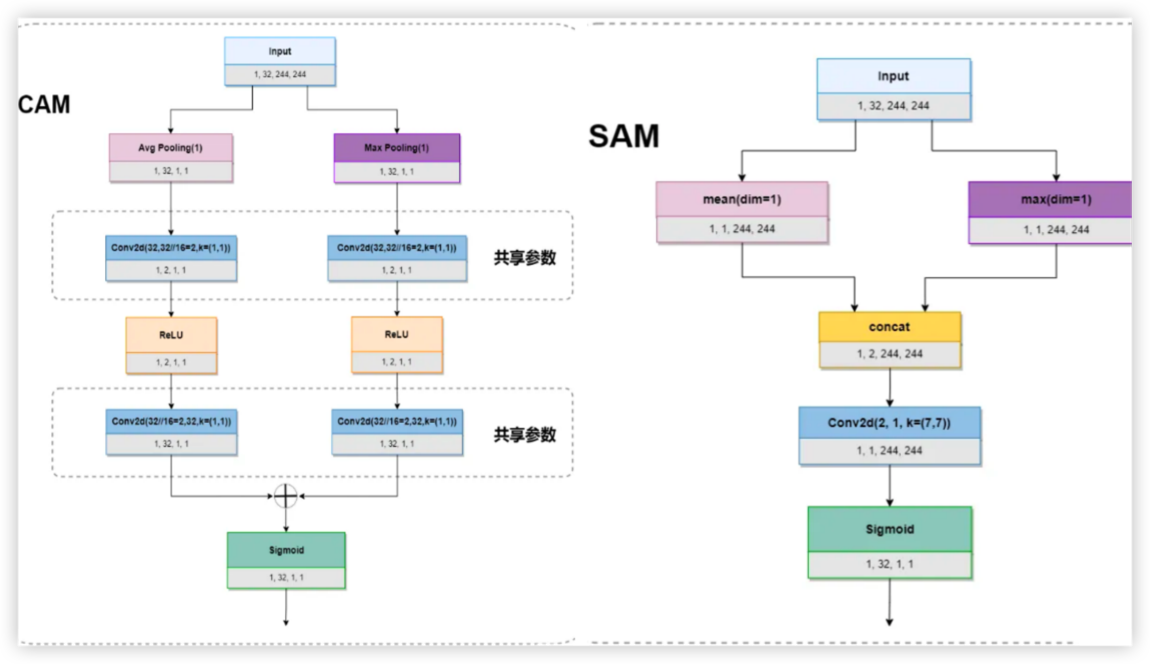
1.CBAM注意力机制
通道注意力模块:关注每个通道的特征图的重要程度
空间注意力模块:关注特征图中的每个像素的重要程度

2.SE注意力机制

3.CA注意力机制

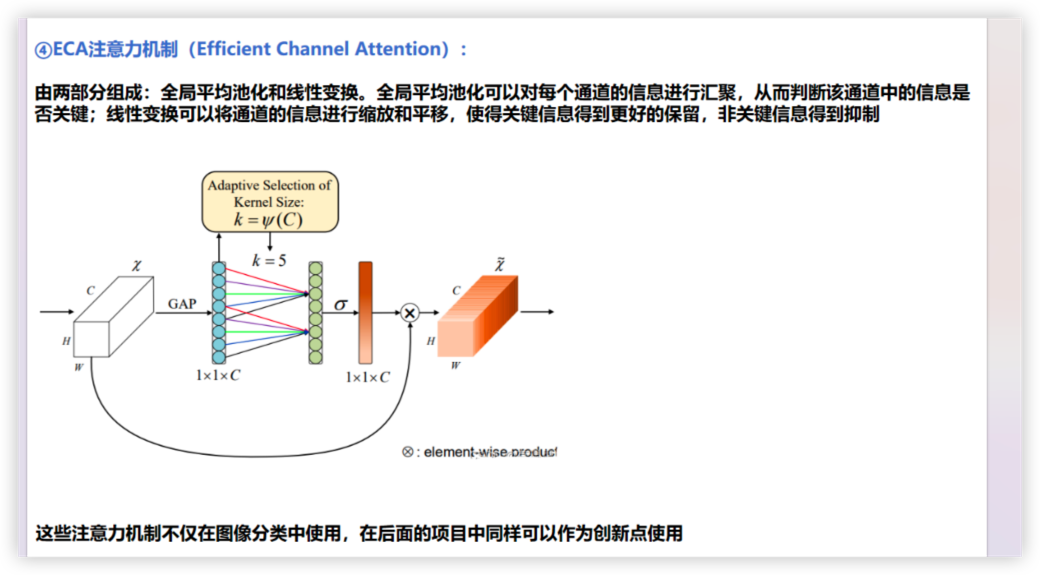
4.ECA注意力机制
目标检测
YOLO算法
YOLO11 网络结构图
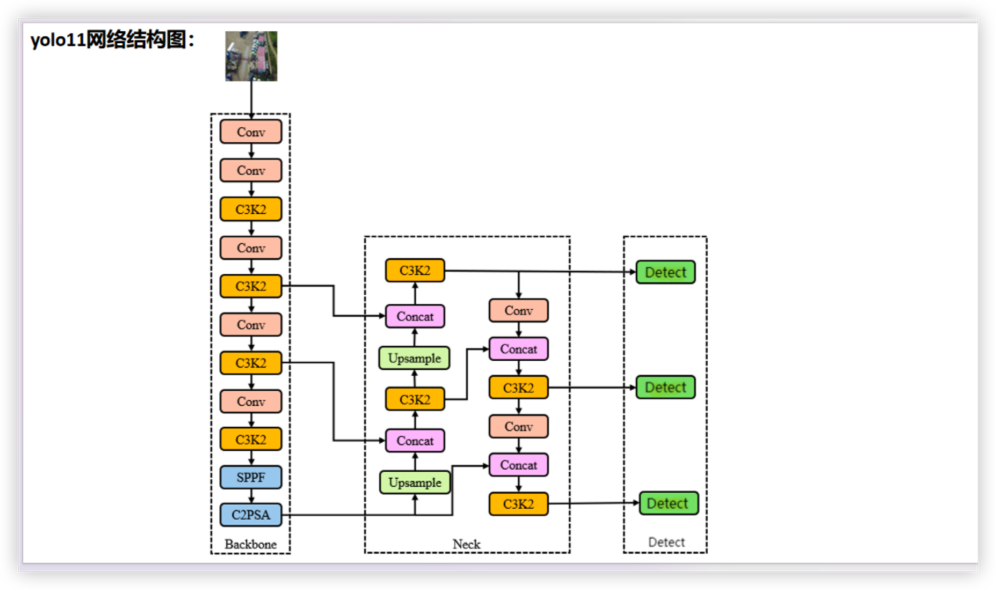

Backbone 特征提取

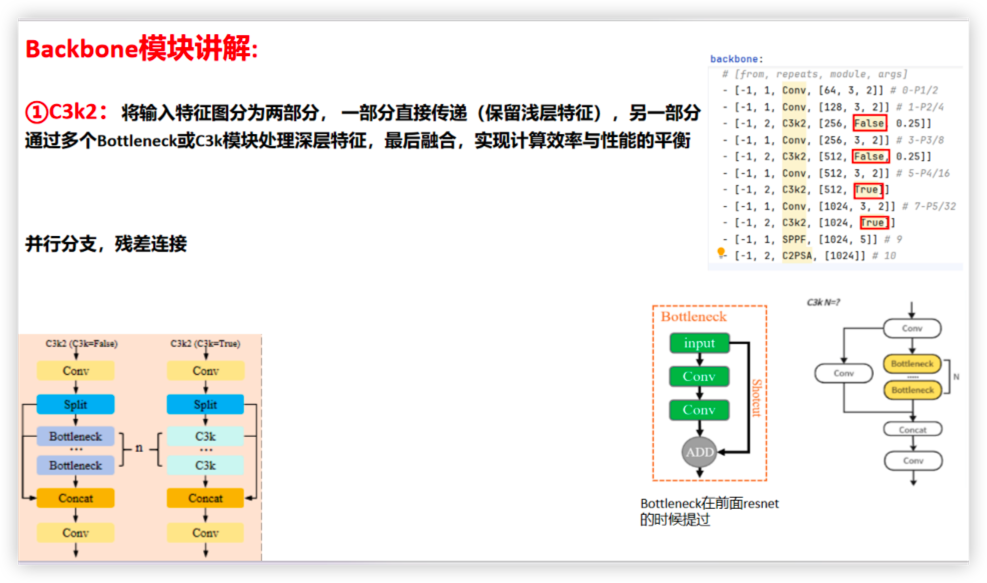
Neck 进行特征融合和增强 + Detect 预测

损失函数


